

Authors - Soheil Esmaeilzadeh, Brian Williams, Davood Shamsi, and Onar Vikingstad
Affiliation - Apple, Cupertino, CA
Abstract - Teachers often conduct surveys in order to collect data from a predefined group of students to gain insights into topics of interest. When analyzing surveys with open-ended textual responses, it is extremely time-consuming, labor-intensive, and difficult to manually process all the responses into an insightful and comprehensive report. In the analysis step, traditionally, the teacher has to read each of the responses and decide on how to group them in order to extract insightful information. Even though it is possible to group the responses only using certain keywords, such an approach would be limited since it not only fails to account for embedded contexts but also cannot detect polysemous words or phrases and semantics that are not expressible in single words. In this work, we present a novel end-to-end context-aware framework that extracts, aggregates, and abbreviates embedded semantic patterns in open-response survey data. Our framework relies on a pre-trained natural language model in order to encode the textual data into semantic vectors. The encoded vectors then get clustered either into an optimally tuned number of groups or into a set of groups with pre-specified titles. In the former case, the clusters are then further analyzed to extract a representative set of keywords or summary sentences that serve as the labels of the clusters. In our framework, for the designated clusters, we finally provide context-aware wordclouds that demonstrate the semantically prominent keywords within each group. Honoring user privacy, we have successfully built the on-device implementation of our framework suitable for real-time analysis on mobile devices and have tested it on a synthetic dataset. Our framework reduces the costs at-scale by automating the process of extracting the most insightful information pieces from survey data.
Keywords: Teachers, Surveys, Open-response, Context-aware, Clustering, Natural language model
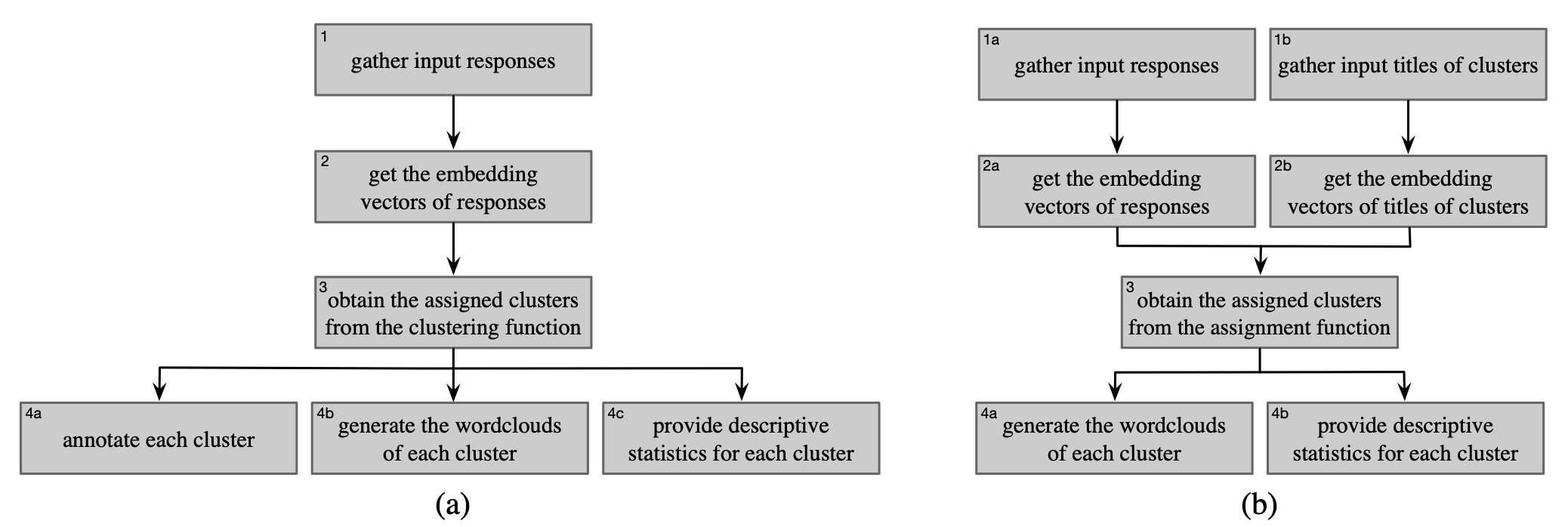
Overview of the steps in (a) context-aware clustering and (b) context-aware cluster assignment. In context-aware clustering (a), we first gather a list of open-responses submitted by students. Next, using the pre-trained language model we generate the embedding vectors of the responses. Afterwards, we obtain the clusters of responses from the clustering function. Finally, we annotate each cluster with an appropriate title (i.e., prominent keywords), generate wordclouds, and provide descriptive statistics for each cluster. In context-aware cluster assignment (b), in the first step, in addition to gathering the list of open-responses we also gather a list of labels of clusters as the input. Next, using the pre-trained language model we generate the embedding vectors for the responses as well as the labels of the clusters. Afterwards, we obtain the clusters of responses from the assignment function. Finally, since the cluster labels are already provided as input, we only generate wordclouds, and provide descriptive statistics for each cluster at the end.

Fig.1. Overview of the cluster assignment approach when sentences and clusters labels are provided as inputs.
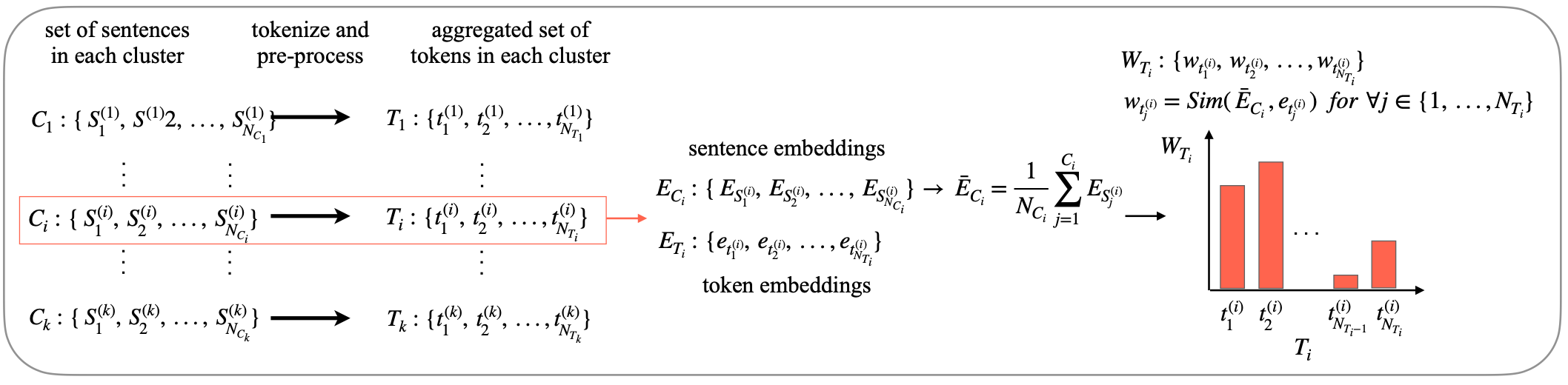
Fig.2. Overview of the cluster annotation approach, i.e., labeling the clusters.
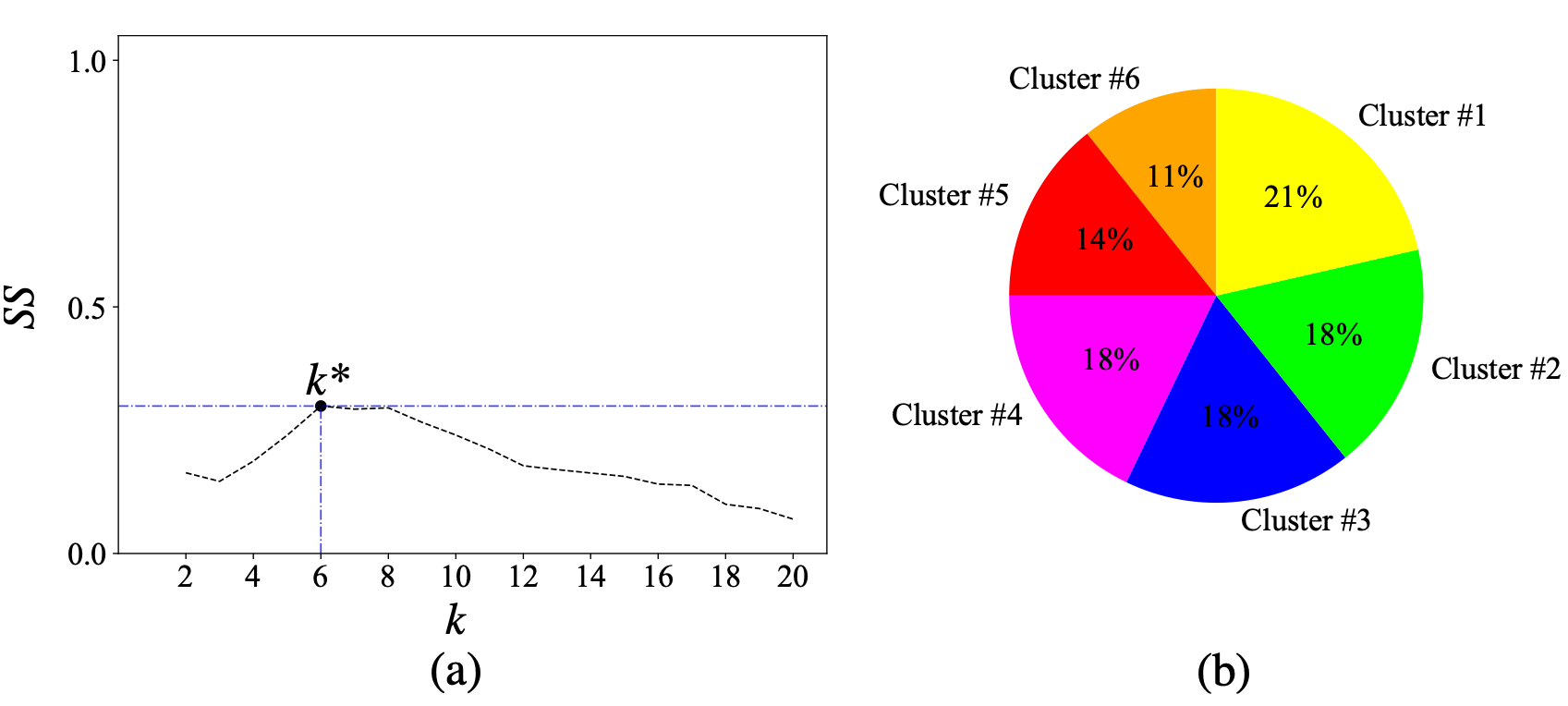
Fig.3. (a) The silhouette score as a function of the number of clusters . (b) The pie chart that shows the distribution of the number of samples that belong to each cluster.
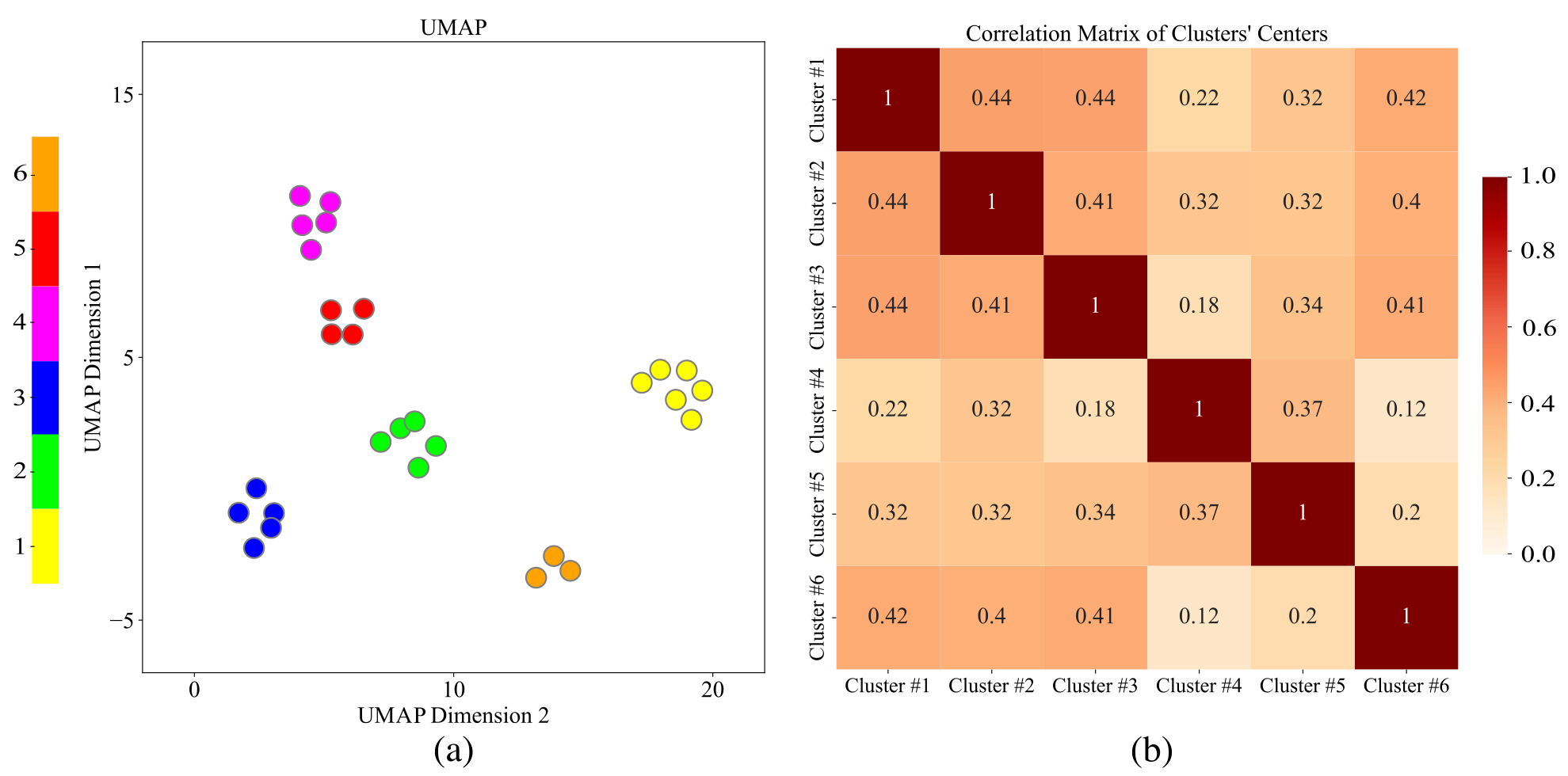
Fig.4. (a) Application of UMAP to the sentence embeddings where the colors represent the clusters. (b) Correlation matrix of clusters’ centers where each entry represents the cosine similarity value between the centroids in a pair of two clusters.
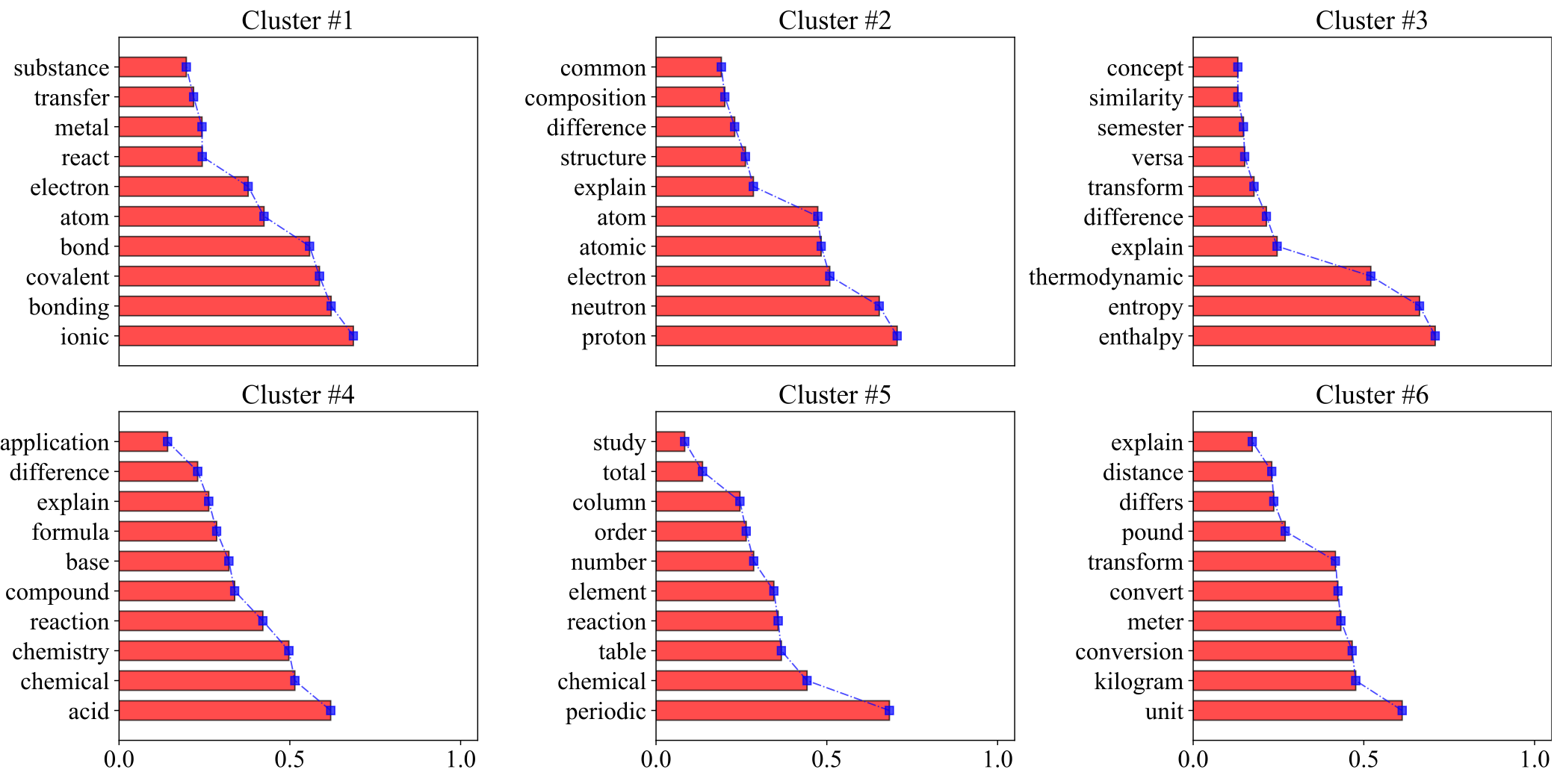
Fig.5. The tokens importance values for the top 10 tokens of each cluster are illustrated.

Fig.6. Wordclouds for the prominent tokens of each cluster are illustrated where the size of words represents the tokens importance values in each cluster. The middle wordcloud shows the unified wordcloud where the colors represent the association of words to each cluster and the size of the words represent the scaled weight values of the prominent tokens.
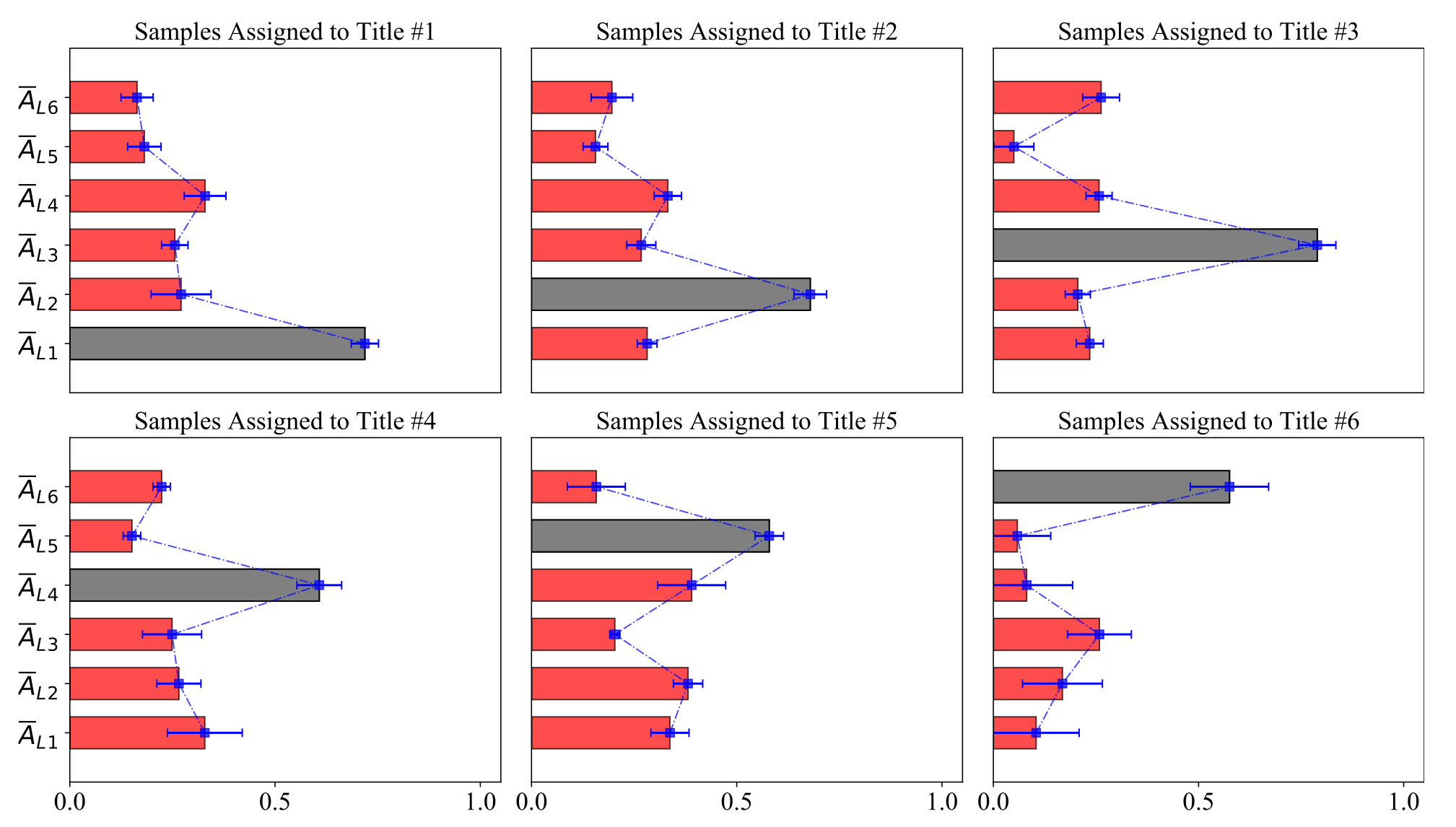
Fig.7. The average (in red) as well as the standard deviation (in blue) values of the assignment matrix for each input cluster label (title) across the samples assigned to each of the input titles.

Function 1a. The pseudo-code for context-aware clustering.

Function 1b. The pseudo-code for context-aware cluster labeling.

Function 2. The pseudo-code for context-aware cluster assignment.